(If you came because of the Bee Gees’ excerpt, congratulations – you’ve just been click-baited.)
Recently, I came across a video on my Facebook news feed, which showed several Hokkien phrases used by Singaporeans – one of which was “cheem”, literally “deep” in English. It is usually used to describe someone being very profound or complex, usually in content and philosophy.
I perceive that despite the geographical differences, there is somewhat a common understanding between the East and the West on the word “deep”. The English term “shallow” means simplistic apart from the lack of physical depth, and so is the phrase “skin deep”.
Of course, the term “deep learning” (DL) does not simply derive from the word “deep” being complicated, but certainly the method of DL is nothing short of being complex.
For this post, I would do the write-up in a slightly different manner – an article of reading will be the “anchor” article in answering each section, and then readings of other articles will be added on to the foundation laid by the “anchor”. For those who pay attention, you would notice the pattern.
My primarily readings will be from the following: Bernard Marr (through Forbes), Jason Brownlee, MATLAB & Simulink, Brittany-Marie Swanson, Robert D. Hof (through MIT Technology Review), Radu Raicea (through freecodecamp.org), and Monical Anderson (through Artificial Understanding and a book by Lauren Huret). As usual, the detailed references are included below.
What is the subject about?
(Now before I go into the readings, I wanted to bring back to how the term “deep learning” was first derived. It was first appeared in academic literature in 1986, when Rina Dechter wrote about “Learning While Searching in Constraint-Satisfaction-Problems” – the paper introduced the term to Machine Learning, but did not shed light on what DL is more commonly known today – neural networks. It was not until the year 2000 that the term was introduced to neural network by Aizenberg & Vandewalle.)
Tracing back to my previous posts, DL is a subset of Machine Learning, which itself is a subset of Artificial Intelligence. Marr pointed out that while Machine Learning took several core ideas of AI and “focuses them on solving real-world problems…designed to mimic our own decision-making”, DL puts further focus on certain Machine Learning tools and techniques in applying to solve “just about any problem which requires “thought” – human or artificial”.
Brownlee offered a different dimension to the definition of DL: “a subfield of machine learning concerned with algorithms inspired by the structure and function of the brain called artificial neural networks”. This definition offered was supported by several more researchers cited in the article, some of them are:
- Andrew Ng (“The idea of deep learning as using brain simulations, hope to: make learning algorithms much better and easier to use; make revolutionary advances in machine learning and AI”)
- Jeff Dean (“When you hear the term deep learning, just think of a large deep neural net. Deep refers to the number of layers typically…I think of them as deep neural networks generally”)
- Peter Norvig (“A kind of learning where the representation you form have several levels of abstraction, rather than a direct input to output”)
The article as a whole was rather academic in nature, but also offered a simplified summary: “deep learning is just very big neural networks on a lot more data, requiring bigger computers”.
The description of DL as a larger-scale, multi-layer neural network was supported by Swanson’s article. The idea of a neural network mimicking a human brain was reiterated in Hof’s article.
How does it work?
Marr described how DL works as having a large amount of data fed through “logical constructions asking a series of binary true/false questions, or extract a numerical value, of every bit of data which pass through them, before classifying them according to the answers received” known as neural networks, in order to make decisions about other data.
Marr’s article gave an example of a system designed to record and report the number of vehicles of a particular make and model passing along a public road. The system would first fed with a large database of car types and their details, of which the system would process (hence “learning”) and compare with data from its sensors – by doing so, the system could classify the type of vehicles that passed by with some probability of accuracy. Marr further explained that the system would increase that probability by “training” itself with new data – and thus new differentiators – it receives. This, according to Marr, is what makes the learning “deep”.
Brownlee’s article, through its aggregation of prior academic researches and presentations, pointed out that the “deep” refers to the multiple layers within the neural network models – of which the systems used to learn representations of data “at a higher, slightly more abstract level”. The article also highlighted the key aspect of DL: “these layers of features are not designed by human engineers: they are learned from data using a general-purpose learning procedure”.
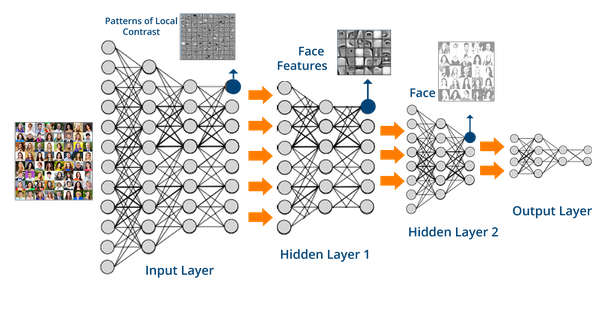
Raicea illustrated the idea of neural networks as neurons having grouped into three different types of layers: input layer, hidden layer(s) and output layer – the “deep” would refer to having more than one hidden layer. The computation is facilitated by connections between neurons that are associated with a (randomly set) weight which dictates the importance of the input value. The system would iterate through the data set and compare the outputs to see how much it is far off from the real outputs, before readjusting the weights between neurons.
How does it impact (in a good way)?
Marr cited several applications of DL that are currently deployed or under work-in-progress. DL’s use-case in object recognition would enhance the development of self-driving cars, while DL techniques would aid in the development of medicine “genetically tailored to an individual’s genome”. Something closer to the layman and Average Joe, DL systems are empowered to analyse data and produce reports in natural-sounding human language with corresponding infographics – this could be seen in some news reports generated by what we know as “robots”.
Brownlee’s article did not expound much on the use-cases. Nevertheless, it highlighted that “DL excels on problem domains where the input (and even output) are analog”. In other words, DL does not need data to come in numerical and in tables, and neither should the data it produces – offering a qualitative dimension to analysis as compared to conventional data analysis.
Much of the explicit benefits were discussed in the prior posts on Machine Learning and Artificial Intelligence.
What are the issues?
Brownlee recapped the prior issues of DL in the 1990s through Geoff Hinton’s slide: back then, datasets were too small, computing power was too weak, and generally the methods of operating it were improper. MATLAB & Simulink pointed out that DL became useful because the first two factors of failures have seen great improvements over time.
Swanson briefly warned on the issue of using multiple layers in the neural network: “more layers means your model will require more parameters and computational resources and is more likely to become overfit”.
Hof cited points raised by DL critics, chiefly on how the development of DL and AI in general have deviated away from putting into consideration how an actual brain functions “in favour of brute-force computing”. An example was captured by Jeff Hawkins on how DL failed to take into consideration the concept of time, in which human learning (which AIs supposed to emulate) would depend on the ability to recall sequences of patterns, and not merely still images.
Hof also mentioned that current DL applications are within speech and image recognition, and to extend the applications beyond them would “require more conceptual and software breakthroughs” as well as advancements in processing power.
Much of other DL’s issues were rather similar to those faced by Machine Learning and Artificial Intelligence, in which I have captured accordingly in the previous posts. One of the recurring themes would be how inexplicable DL systems get to its output, or in the words of Anderson’s article, “the process itself isn’t scientific”.
How do we respond?
Usually, I would comment in this section with very forward-looking, society-challenging calls for action – and indeed I have done for the post on AI and Machine Learning.
But I would like to end with a couple of paragraphs from Anderson in a separate publication, which captured the anxiety about AI in general, and some hope for DL:
“A computer programmed in the traditional way has no clue about what matters. So therefore we have had programmers who know what matters creating models and entering these models into the computer. All programming is like that; a programmer is basically somebody who does reduction all day. They look at the rich world and they make models that they enter into the computer as programs. The programmers are intelligent, but the program is not. And this was true for all old style reductionist AI.
… All intelligences are fallible. That is an absolute natural law. There is no such thing as an infallible intelligence ever. If you want to make an artificial intelligence, the stupid way is to keep doing the same thing. That is a losing proposition for multiple reasons. The most obvious one is that the world is very large, with a lot of things in it, which may matter or not, depending on the situations. Comprehensive models of the world are impossible, even more so if you considered the so-called “frame problem”: If you program an AI based on models, the model is obsolete the moment you make it, since the programmer can never keep up with the constant changes of the world evolving.
Using such a model to make decisions is inevitably going to output mistakes. The reduction process is basically a scientific approach, building a model and testing it. This is a scientific form of making what some people call intelligence. The problem is not that we are trying to make something scientific, we are trying to make the scientist. We are trying to create a machine that can do the reduction the programmer is doing because nothing else counts as intelligent.
… Out of hundreds of things that we have tried to make AI work, neural networks are the only one that is actually going to succeed in producing anything interesting. It’s not surprising because these networks are a little bit more like the brain. We are not necessarily modeling them after the brain but trying to solve similar problems ends up in a similar design.”
Interesting Video Resources
But what *is* a Neural Network? | Chapter 1, deep learning – 3Blue1Brown: https://youtu.be/aircAruvnKk
How Machines *Really* Learn. [Footnote] – CGP Grey: https://www.youtube.com/watch?v=wvWpdrfoEv0
References
What Is The Difference Between Deep Learning, Machine Learning and AI? – Forbes: https://www.forbes.com/sites/bernardmarr/2016/12/08/what-is-the-difference-between-deep-learning-machine-learning-and-ai/#394c09c726cf
What is Deep Learning? – Jason Brownlee: https://machinelearningmastery.com/what-is-deep-learning/
What Is Deep Learning? | How It Works, Techniques & Applications – MATLAB & Simulink: https://www.mathworks.com/discovery/deep-learning.html
What is Deep Learning? – Brittany-Marie Swanson: https://www.datascience.com/blog/what-is-deep-learning
Deep Learning – MIT Technology Review: https://www.technologyreview.com/s/513696/deep-learning/
Want to know how Deep Learning works? Here’s a quick guide for everyone. – Radu Raicea: https://medium.freecodecamp.org/want-to-know-how-deep-learning-works-heres-a-quick-guide-for-everyone-1aedeca88076
Why Deep Learning Works – Artificial Understanding – Artificial Understanding: https://artificial-understanding.com/why-deep-learning-works-1b0184686af6
Artificial Fear Intelligence of Death. In conversation with Monica Anderson, Erik Davis, R.U. Sirius and Dag Spicer – Lauren Huret: https://books.google.com.my/books?id=H0kUDAAAQBAJ&dq=all+intelligences+are+fallible&source=gbs_navlinks_s


